Challenge
Quadratic Knapsack Problem
Gene cluster analysis: Understanding genetic diseases.
Performance Overview
Speed vs IHEA
85×
faster execution
Speed vs QKBP
4.1×
faster execution
Quality vs QKBP
21×
better solution quality
This chart shows the solution quality evolution using the Relative Percentage Deviation (RPD) from optimal solutions, displayed on a logarithmic scale. Lower RPD values indicate better performance, with our transformation positioning better quality higher on the plot. Results are combined from testing on benchmark instances ranging from size 100 to 10,000 (StandardQKP, QKPGroupII, QKPGroupIII, and LargeQKP).
From round 64 onwards, TIG algorithms demonstrate superior solution quality compared to established state-of-the-art methods. The consistent improvement in RPD values shows how our competitive ecosystem drives algorithmic innovation, achieving solutions that are 21× better than QKBP (2025).
The dramatic improvement from round 44 to 64 illustrates the power of iterative refinement within the TIG protocol, where each algorithm builds upon previous innovations while competing for rewards. Read the complete research analysis for detailed methodology and benchmarking results.
Problem Overview
The quadratic knapsack problem is one of the most popular variants of the single knapsack problem, with applications in many optimization contexts.
The aim is to maximize the value of individual items placed in the knapsack while satisfying a weight constraint. However, pairs of items also have positive interaction values, contributing to the total value within the knapsack.
Applications
The Knapsack problems have a wide variety of practical applications. The use of knapsack in integer programming led to breakthroughs in several disciplines, including energy management and cellular network frequency planning.
Although originally studied in the context of logistics, Knapsack problems appear regularly in diverse areas of science and technology. For example, in gene expression data, there are usually thousands of genes, but only a subset of them are informative for a specific problem. The Knapsack Problem can be used to select a subset of genes (items) that maximizes the total information (value) without exceeding the limit of the number of genes that can be included in the analysis (weight limit).
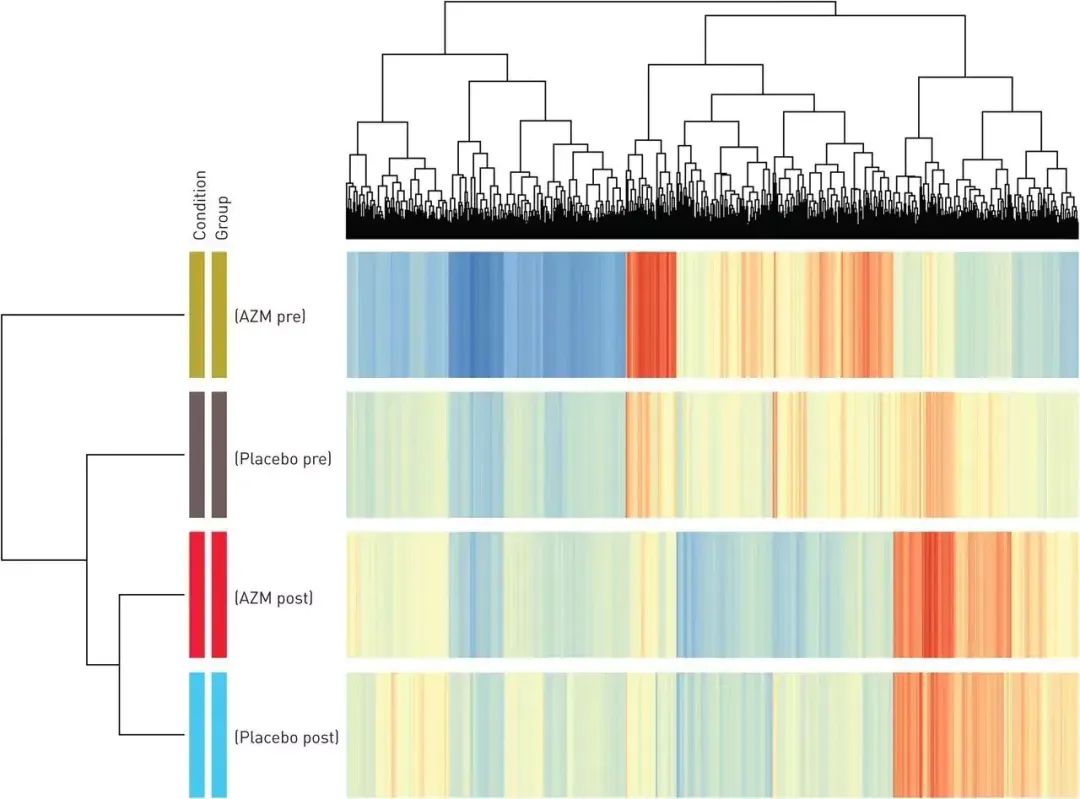
Figure 1: Microarray clustering of differentially expressed genes in blood. Genes are clustered in rows, with red indicating high expression, yellow intermediate expression and blue low expression. The Knapsack problem is used to analyse gene expression clustering.